
こんにちは、毛糸です。
先日の記事で、株価の日次リターンが正規分布に従わないことを確認しました。
>>日本株式、米国株式、欧州株式、全世界株式の日次リターンが正規分布ではなかった件
本ブログでたびたび登場する投資シミュレーションプログラムは、リターンが正規分布に従うと仮定した場合の将来予測ツールなので、正規分布に従わないことがわかった今、何らかの改善をしなくてはなりません。
>>「投資シミュレーションプログラム」サマリー
本記事では改善のための手法として考えている「ブートストラップ法」について解説し、ブートストラップ法を株価リターン分布の推定にどう利用できるかを説明します。
なお、本記事は下記サイトの内容を参考にしています。
>>Rで「ブーツ」(PDFリンク)
ブートストラップ法とはデータを無作為抽出し推定に使う手法
>>「投資シミュレーションプログラム」サマリー
株価リターンにブートストラップ法を適用する
ブートストラップ法によれば、株価リターンのデータから、無作為にデータを抽出し、新たなデータとして扱うことになります。
これにより、リターンが正規分布に従うと仮定できなくても、実際の株価リターンデータを乱数のように用いて、統計的・確率論的な分析が可能になります。
実際に、日本株式のリターンを使って、分析を行ってみましょう。
まず、下記の記事を参考に、日本株式のリターンのデータを読み込みます。
>>ファーマ-フレンチの3ファクターモデルのデータを入手する方法
#csvデータの読み込み
JP <- read.csv("Japan_3_Factors_Daily.csv", skip=5)
#時系列データとして加工
JP_mkt<-ts(JP$Mkt.RF+JP$RF,start=JP$X[1])/100
日本株の日次リターンの統計量を求めてみます。
#平均 m=mean(JP_mkt) #標準偏差 s=sd(JP_mkt) library(moments) #歪度:正規分布が0 skewness(JP_mkt) skewness(rnorm(10000,m,s)) #尖度:正規分布が3 kurtosis(JP_mkt) kurtosis(rnorm(10000,m,s))
株価リターンと同じ平均、標準偏差をもつ正規分布より、尖度はかなり大きな値になっていることがわかります。
データが正規分布に従うかを調べるための、コルモゴロフ・スミルノフ検定も行っていますが、「正規分布に従う」という帰無仮説は棄却され、株価リターンは正規分布ではないと結論付けられます。
#コルモゴロフ・スミルノフ検定 ks.test(JP_mkt, "pnorm", mean=m, sd=s)
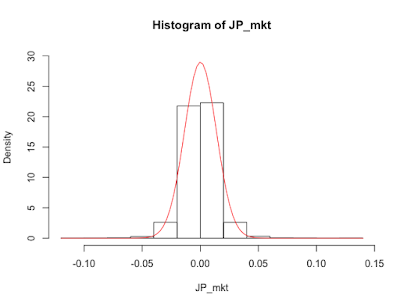
ヒストグラムを正規分布と比較してみます。実際の株価リターンデータと、同じ平均、標準偏差の正規分布の密度関数を描きます。実際のデータのほうが、左右の裾が厚い感じがします。
hist(JP_mkt,freq = FALSE,ylim=c(0,30)) curve(dnorm(x,m,s),add=TRUE,col="red")
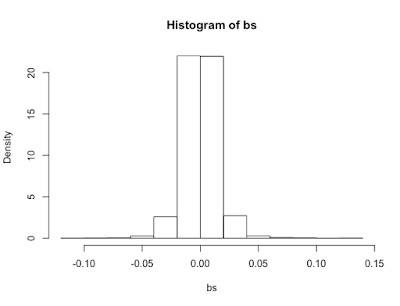
株価リターンにブートストラップ法を適用してみます。株価リターンから、無作為に10000個のサンプルを抽出し、ヒストグラムを描きます。
#ブートストラップ法
bs<-sample(JP_mkt,10000,replace=T) hist(bs,freq = FALSE)
ブートストラップ法で得たサンプルを使って、損失確率を計算し、正規分布の場合と比較してみましょう。
#損失確率ブートストラップ法 length(bs[bs<0])/length(bs) #損失確率正規分布 pnorm(0,m,s)
ブートストラップ法で得たサンプルから計算した損失確率は49.2%、正規分布の場合は49.5%でしたので、実際のデータのほうがやや損失が出にくい(利益が出やすい)分布であることがわかりました。
損失確率を求めるくらいであれば、データをそのまま使えばよいので、ブートストラップ法を適用する必要もありませんが、より複雑な分析をするときには、ブートストラップ法は強力なツールになります。
まとめ
ブートストラップ法の概要と、株価リターン分析への応用可能性について説明しました。
実際の株価リターンは、理論で前提とするような正規分布ではありませんが、だからといって理論の価値が損なわれるわけではありません。
正規分布との差異をきちんと把握し、必要ならば適切に対処できることが大事です。
>>理論・モデルの意義と、理論と現実の差異を知ったあとにとるべき行動