
「AIやロボットによって、人間は単純作業から開放され、付加価値の高い業務に集中できる」
そんな声を聞きます。
本当にAIは私たちの仕事を楽にしてくれるのでしょうか?
本記事は「AIで私たちは単純作業から開放されるのか」という主張に対する私見を述べつつ、高付加価値業務にシフトすることの難しさに触れながら、来るべきAI時代を前に私達は何をすべきかを考察します。
「AIやロボットによって、人間は単純作業から開放され、付加価値の高い業務に集中できる」
そんな声を聞きます。
本当にAIは私たちの仕事を楽にしてくれるのでしょうか?
本記事は「AIで私たちは単純作業から開放されるのか」という主張に対する私見を述べつつ、高付加価値業務にシフトすることの難しさに触れながら、来るべきAI時代を前に私達は何をすべきかを考察します。

こんにちは、毛糸です。
AIやブロックチェーンなど、新しいテクノロジーが次々と生まれては、またたくまにビジネスに適用されていくのが今の時代です。
テクノロジーは我々の仕事を効率化し、人間がより人間らしく働くことの後押しをしてくれると期待されていますが、一方で「仕事を奪われる」という脅威論もしばしば見られます。
この主張は果たして信じて良いのでしょうか。

こんにちは、毛糸です。
AI(人工知能)という言葉が広く知られるようになり、Deep learningのようなブレイクスルーがビジネスにも応用されつつあります。
AIは時折「人間の仕事を奪う」という文脈で脅威的な存在として語られることもあり、2013年のカール・ベネディクト・フレイとマイケル A. オズボーンの論文
「THE FUTURE OF EMPLOYMENT: HOW SUSCEPTIBLE ARE JOBS TO COMPUTERISATION?」(pdfリンク)
では多くの職業がコンピュータに取って代わられる可能性があることが示されています。
論文内に示される代替確率ランキングでは、Bookkeeping, Accounting, and Auditing Clerks(簿記、会計および監査職員)は702の職業のうち、代替確率が低い順に671位、代替されやすさでいえば31位に上がっています。
こうした状況の中で「AIで会計士の仕事(監査)はなくなるのか」という話題がしばしば取り上げられます。
本記事ではこの問いに対して、会計の数理モデルに基づく整理を述べ、AIによる監査の代替について考察します。

こんにちは、毛糸です。
先日こんなツイートを見かけました。
「待て、誰だ!」Excel VBA「フィンテックです」
「よし、通れ!」
— まゆずみ君 (@NekoMur) 2019年7月9日
このツイートをパク……いえ、インスパイアされて、こんな呟きをしました。
「待て、誰だ!」Excel VBA「RPAです」
「よし、通れ!」
はマジであるある。
— 毛糸 (@keito_oz) 2019年7月9日
本記事ではこのツイートの内容を深掘りし、VBAをRPAと間違えて通してしまうような状況がどうして起こるのか、その問題はどこにあるのかについて考えてみます。
RPAとは、次世代の新しい労働力と期待される自動化システム(ロボティック・プロセス・オートメーション)のことです。
いまビジネス界ではAIと並ぶ技術として多くの企業が注目し、実際に業務に適用されています。
RPAに関しては、以前開催された勉強会PyCPAでも取り上げられ、大変反響がありました。
RPAは一種のバズワードとして、ビジネスマンなら知らないでは済まされない言葉になりつつあり、企業の「偉い人」たちの中でも、業務に組み込めないものかと画策する人は少なくありません。
冒頭のツイートは、そんなRPAブームを風刺するものです。
RPAは業務アプリケーションをまたぐようなプロセスの自動化を可能にするソフトウェアです。
業務自動化という点に着目すれば、すでに「広く普及したツール」により、ある程度のことは可能になっています。
それがExcelマクロであり、その記述プログラミング言語であるVBAです。
Excel VBAはエクセルの操作の自動化や、他のOfficeソフトやインターネットエクスプローラーとの連携により、様々な処理を自動化可能です。
実際、大企業ではExcel VBAによる大規模なツールを開発・導入し、業務効率化を行っている例が数多くあります。
しかし、RPA全盛期の今、「それExcel VBAでもできますよ」というフレーズは、「偉い人」たちの心には刺さりません。
「RPAじゃないの?それじゃあだめだよ、RPAを使わなくちゃ」
と一蹴され、RPAではなくExcel VBAでプログラム組みましょうとはなりづらい現状があります。
このような現象はひとえに「RPAを使いたい」ということが目的化していることが原因です。
RPAは本来、従来の方法では自動化できなかったアプリケーション間の連携などを柔軟につなぎ合わせることが可能な技術として、業務改善に用いられるべきものです。
しかし空前の「RPAブーム」によって、「RPAを使うこと」それ自体が目的化し、そのために課題を探すという逆転現象が起こっているのです。
もちろん、RPAという新しい技術が世に広く知られたことで、見えてきた課題もあるでしょう。
スヌーピーでおなじみの漫画ピーナッツにもこんな名言があります。
配られたトランプで勝負するっきゃないのさ……(YOU PLAY WITH THE CARDS YOU’RE DEALT…)
RPAというカードが配られたからには、そのカードを使って勝ちを挙げたい、と考える人は多いでしょう。
しかし他者もやっているからうちも、とか、Excel VBAでできるような比較的簡単な自動処理もRPAでやりたい、とかいう話になってくると、手段と目的が入れ替わっていると言わざるを得ません。
ベストセラーになった『起業の科学』には、事業の成功の条件の1つに、問題と解決策が一致していること(プロブレム・ソリューション・フィット)を挙げています。
起業という文脈を抜きにしても、課題とその解決策が一致していなければその取組みから成果を上げることは難しく、したがって「解決策(RPA)」ありきで課題を見つけるようなやり方が、常にうまくいくとは限りません。
ましてや冒頭のように、Excel VBAを「RPAです」と言って「よしよし」と納得してしまうのは、RPAという技術がなんたるかを知らないばかりか、自分の課題すらも見失っているのではないかと心配になる状況です。
残念ながら、こんな笑い話のような状況が、たまに見聞きされるのです。

こんにちは、毛糸です。
株式の期待リターンを推定するために広く用いられているのが、CAPM(Capital Asset Pricing Model)です。
CAPMは株式のリターンを市場ポートフォリオの1次関数として表す、とてもわかり易いモデルです。
本記事ではCAPMの計算(具体的には、ベータの推定)を、統計プログラミング言語Rで行う方法についてまとめます。
CAPMにおけるベータの推定には、個別株式と市場ポートフォリオのリターンのデータが必要になりますが、quantmodというパッケージを使えば、簡単に取得できるため、その方法も説明します。
また、推定に必要な無リスク金利(安全資産利子率)には、財務省が公表している国債利回りを用いることとします。
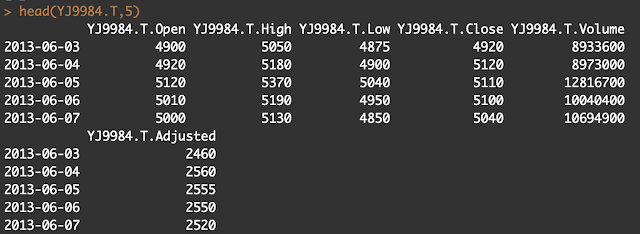
こんにちは、毛糸です。
2019年6月26日現在、ビットコイン価格が再び高騰しており、135万円を超えました。
ビットコインを始めとする仮想通貨(暗号資産)は2017年頃に劇的な価格高騰を引き起こし、現代の「バブル」として社会に大きな影響を与えました。
参考記事>>ビットコインはバブルである
リンクの記事でも述べたとおり、仮想通貨はキャッシュフローの裏付けがなく、厳密な意味で「資産」と呼べるか微妙な投資対象です。
基本的には「明日は今日より高くなる」という期待が価格形成に寄与する「バブル」的性格を持つと考えれます。
バブル資産としての仮想通貨は、その特徴的な価格変動やリターンの非正規性など、既存のファイナンス理論では説明しづらい部分が多くあります。
>>ビットコインの確率分布について|期待リターン、リスク、ヒストグラム【正規分布じゃない】
仮想通貨を理論的に扱おうとする場合には、バブル資産としての特徴を考慮する必要がありますが、バブル資産の理論研究は相対的に未成熟な分野です。
本記事ではファイナンス(金融工学)の立場からバブル資産を研究した文献をメモしておきます。
こちらもバブル資産を「局所マルチンゲール」としてモデル化し種々の分析を行っています。
局所マルチンゲールを含む確率過程論や確率微分方程式という数学は、理系大学の学部後半から大学院にかけて学ぶ内容であり、比較的高度です。
ファイナンスの数理的研究はこうした確率論と密接に結びついていますので、バブルの研究にも確率論の勉強は避けては通れないでしょう。
ファイナンスにも言及している、確率過程や確率微分方程式を扱ったテキストとしては以下が参考になります。

こんにちは、毛糸です。
先日の記事で、主要地域の株価リターンが正規分布に従わないことを確かめました。
>>日本株式、米国株式、欧州株式、全世界株式の日次リターンが正規分布ではなかった件
参考記事>>分散投資を批判した後の対案がそれ以上に酷い法則-梅屋敷商店街のランダム・ウォーカー(インデックス投資実践記)
今回はファイナンス理論の観点から、正規分布が成り立たない場合にも、既存のファイナンス理論は通用するのだということを説明します。
なお、本記事は以下の書籍の内容を参考にしているので、興味のある方はチェックしてみてください。
下記の記事で述べたとおり、主要地域の株価の日次リターンは、正規分布に従いません。
>>日本株式、米国株式、欧州株式、全世界株式の日次リターンが正規分布ではなかった件
投資期間が短い場合の株価リターンは正規分布に従わない、というのは学術的にも古くから指摘されており、また、投資期間が長い場合は正規性を棄却できないとする研究もあります。
ファイナンスの多くの理論研究は、資産収益が正規分布に従うことを仮定しており、正規分布と仮定しているからこそ見つかった性質というのも数多くあります。
しかし、ファイナンスの理論研究の多くは「モデル分析」、すなわち現実の問題の本質的な部分を切り取り抽象化して、他の部分は削ぎ落とした世界で成り立つ性質を調べる、というものです。
したがって、正規分布という仮定それ自体が、ある種の「捨象」であり、正規分布であることが本質的に重要でないことも多くあります。
仮に現実の株価リターンが正規分布でなくとも、ファイナンス理論の得た洞察が揺らぐものではありませんし、もし正規分布という過程によって揺らぐような理論を利用したいのであれば、自ら理論を修正すれば良いだけの話です。
>>理論・モデルの意義と、理論と現実の差異を知ったあとにとるべき行動
ファイナンスの標準的モデルが正規分布を使っているといっても、正規分布以外の分布の可能性を一切捨てているわけではなく、正規分布以外の分布で成り立つ命題を多くの研究者が探求しています。
投資理論においては、収益の平均(リターン)と分散(標準偏差、リスク)の情報を基に最適なポートフォリオを探求するという研究が、1950年台のマーコウィッツの研究以後、活発に調査されてきました。
このマーコウィッツの平均分散分析は、ノーベル経済学賞の受賞理由にもなり、昨今話題になっているロボアドバイザーの技術的根拠、さらには投資の王道「分散投資」の理論的裏付けにもなっています。
平均分散分析が成り立つためには、リターンが正規分布にしたがう、というのが十分条件になっています。
つまり、正規分布ならば平均分散分析が成り立つ、ということです。
現実には「正規分布ならば」が成り立っていませんので、平均分散分析が成り立つかはわかりません。
この点をもって「前提が破綻している!理論は不完全だ!」というのはあまりにも非論理的です。
正規分布でなくても、平均分散分析を成り立たせるような、別の十分条件があるかもしれないからです。
事実、その後の意欲的な研究により、リターンが正規分布でなくとも、楕円分布族というクラスに属していれば、平均分散分析(と同様の分析)が行えることがわかっています。
楕円分布族というのは、平たく言うとを横に輪切りにしたときの切り口が楕円(正規分布は正円です)になるような分布のことで、正規分布の他に、対称安定パレート分布、t分布、分散混合の混合正規分布などがあります。
株価リターンがこれら分布に従えば、ポートフォリオのリターンも楕円分布に従うことがわかっています。
このとき、ある投資家は資産リターンが正規分布だと思い、別の投資家は安定分布だと思っていたとしても、パラメタが同じなら平均分散分析は成り立つちます。
ややテクニカルな話になりましたが、平均分散分析や分散投資という理論は、リターンが正規分布に従うという仮定でなくとも、本質的な部分は変わることなく成り立つということです。
資金の出入りを反映させるに伴い、まず期間を原則として月数とするようにし、投資月数をhorizonという変数に格納します。
#投資年数(自由入力) Year<-1 #1年あたりの月数(通常は12) Month_par_year<-12 #投資月数 horizon<-Year*Month_par_year#monthes
また、投資期間中の資金の出入りを、inv_schedule変数に格納します。たとえば、毎月1万円の積立投資を行う場合には、指定した数字を繰り返す関数rep()を用いて、以下のように記述します。
#投資スケジュールを入力(自由入力) inv_schedule<-rep(1,horizon)
投資のリスク・リターンも、月次ベースに直します。
#年率期待リターン(期待収益率μ、自由入力) mu<-7/100 mu_par_month<-mu/Month_par_year #年率リスク(標準偏差σ、自由入力) sigma<-12.88/100 sigma_par_month<-sigma/(Month_par_year)^0.5
シミュレーションを行う繰り返し計算の部分に、前述のinv_scheduleの各要素を足すように変更します。
#シミュレーション開始
for (s in 1:sample){
for ( t in 1:horizon){
#撤退していれば計算を飛ばす
if(W[s]==1) break
#今年の資産額=前年の資産額*(1+レバ比率*収益率)
A[s,t+1]<-A[s,t]*(1+Lev*z[s,t])+inv_schedule[t]
#もし資産額が撤退額を下回ったら撤退目印を立てる
if(A[s,t+1]<Withdraw)W[s]<-1
}
}
#投資年数(自由入力)
Year<-1
#1年あたりの月数(通常は12)
Month_par_year<-12
#投資月数
horizon<-Year*Month_par_year#monthes
#シミュレーション回数(自由入力、多いほど正確だが時間がかかる)
sample<-1000
#シミュレーション数値を格納する行列
A<-matrix(0,sample,horizon+1)
#初期投資額を入力(自由入力)
initial<-1000
#投資スケジュールを入力(自由入力)
inv_schedule<-rep(1,horizon)
#シミュレーション数値に初期投資額を入力
A[,1]<-initial
#年率期待リターン(期待収益率μ、自由入力)
mu<-7/100
mu_par_month<-mu/Month_par_year
#年率リスク(標準偏差σ、自由入力)
sigma<-12.88/100
sigma_par_month<-sigma/(Month_par_year)^0.5
#レバレッジ比率
Lev<-1
#撤退をカウントする目印
W<-rep(0,sample)
#撤退額を設定
Withdraw<-0
#乱数を生成(ランダムな投資収益率)
set.seed(1234)
x<-rnorm(sample*horizon,mu_par_month,sigma_par_month)
#乱数(ランダムな収益率)を行列形式に変換
z<-matrix(x,sample,horizon)
#シミュレーション開始
for (s in 1:sample){
for ( t in 1:horizon){
#撤退していれば計算を飛ばす
if(W[s]==1) break
#今年の資産額=前年の資産額*(1+レバ比率*収益率)
A[s,t+1]<-A[s,t]*(1+Lev*z[s,t])+inv_schedule[t]
#もし資産額が撤退額を下回ったら撤退目印を立てる
if(A[s,t+1]<Withdraw)W[s]<-1
}
}
#シミュレーション結果の期待値を表示
paste(Year,"年後の資産額の期待値は",mean(A[,horizon+1]))
#シミュレーション結果の中央値を表示
paste(Year,"年後の資産額の中央値は",median(A[,horizon+1]))
#損する確率を表示
paste("損失を被る確率は",length(A[,horizon+1][A[,horizon+1]<initial])/sample)
#億り人になれる確率を表示
paste("億り人になれる確率は",length(A[,horizon+1][A[,horizon+1]>10000])/sample)
#破産する確率を表示
paste("破産する確率は",sum(W)/sample)
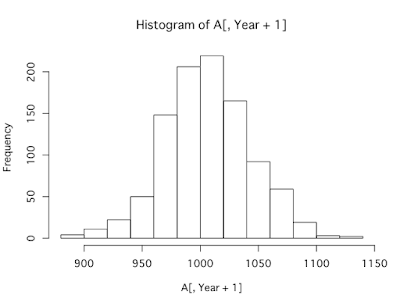
#将来の資産額の確率分布(ヒストグラム)を表示
hist(A[,Year+1])


こんにちは、毛糸です。
ドルコスト平均法は投資手法の一つであり、決まった期間ごと(たとえば一ヶ月ごと)に一定の金額を投資することを指します。
ドルコスト平均法は投資の平均買い付け価格を下げる効果があるとされています。
しかし、ドルコスト平均法が投資手法として優れているのかというのは、学術的には肯定的な意見も否定的な意見もあり、科学的に立証された方法ではありません。
資産運用の初心者におすすめの入門書『難しいことはわかりませんが、お金の増やし方を教えてください!』には、ドルコスト平均法について、
三流ファイナンシャルプランナーが書いたんじゃない?
早めに買ってお金に働いてもらう期間が長いほうが、現時点の判断としては正しい。
と書かれており、ドルコスト平均法に否定的です。
このように、専門家の間でもドルコスト平均法の有効性については判断が分かれています。
こういうケースにおいては、ドルコスト平均法によって、買い付け単価の平均は小さく抑えられます。
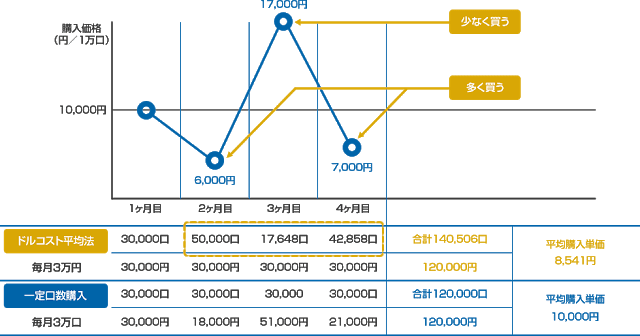
出典:三井住友DSアセットマネジメントhttps://www.daiwasbi.co.jp/fundcollege/investment/about/index4.html
したがって、特定期間のデータに依拠したドルコスト平均法の分析は説得力にかけるものがほとんどです。
データ期間に依存しない一般的なケースでの分析が難しいことが、ドルコスト平均法の分析を難しくする要因のひとつとなっています。
計算によって、この購入量もまた、対数正規分布に従うことがわかります。
数式で書くと、時点\( t\)において資産価格が\( S_t\)だったときに、一定額\( A\)を投資したときの購入量\(Q_t \)は、以下のように表すことができ、これは対数正規分布に従います。
ただし、\( \mu\)は資産の期待リターン、\( \sigma\)はリスク、\( W_t\)は正規分布に従う確率変数です。
こんにちは、毛糸です。
前回、Rライブラリ「crypto」を用いて、仮想通貨の価格が簡単に取得できることを説明しました。
>>仮想通貨の価格ヒストリカルデータを取得する方法|Rライブラリcryptoの使い方
今回は「crypto」を使って取得したBitcoin(BTC)の価格情報を分析します。
BTC価格の時系列データを分析することで、BTCの期待リターン、リスクが極めて高いことがわかりました。
また、ヒストグラムと「正規性の検定」により、BTCのリターンは正規分布に従わないこともわかりました。
cryptoパッケージのcrypto_history()関数を用いて、BTC価格のヒストリカルデータを取得します。
>>仮想通貨の価格ヒストリカルデータを取得する方法|Rライブラリcryptoの使い方
#crypto_history(coin = NULL, limit = NULL, start_date = NULL, #end_date = NULL, coin_list = NULL, sleep = NULL) #仮想通貨の価格等情報を取得 #dateはyyyymmdd形式で。NULLとすると最長期間 BTC<-crypto_history(coin = "BTC", start_date = NULL,end_date = NULL)
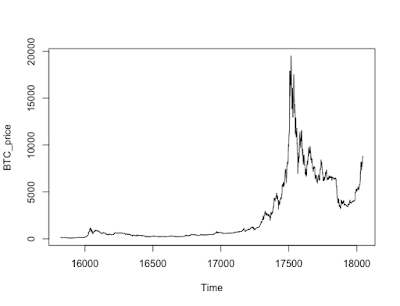
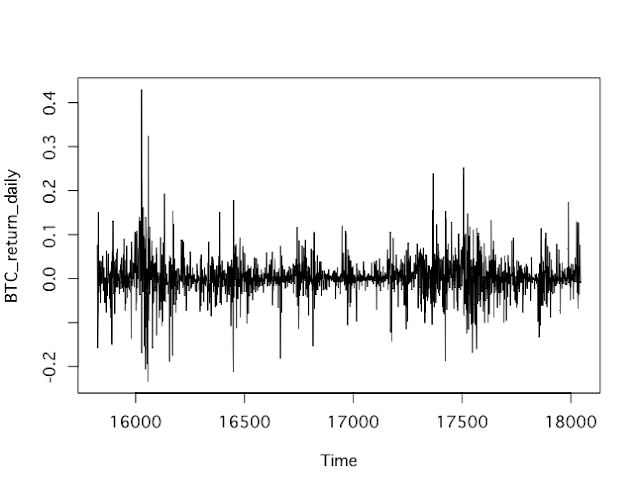
BTC_price<-ts(BTC$close,start=BTC$date[1]) plot(BTC_price,type="l")
#日次収益率 BTC_return_daily<-diff(BTC_price,lag=1)/lag(BTC_price,k=-1) plot(BTC_return_daily,type="l")
#日次収益率の平均(期待リターン)(%) mean(BTC_return_daily)*100 #[1] 0.2808807 #年率換算(%) mean(BTC_return_daily)*100*365 #[1] 102.5215
#標準偏差(%) sd(BTC_return_daily)*100 #[1] 4.333606 #年率換算(%) sd(BTC_return_daily)*100*365^0.5 #[1] 82.79343
install.packages("moments")
library(moments)
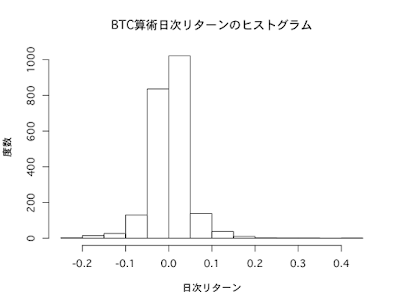
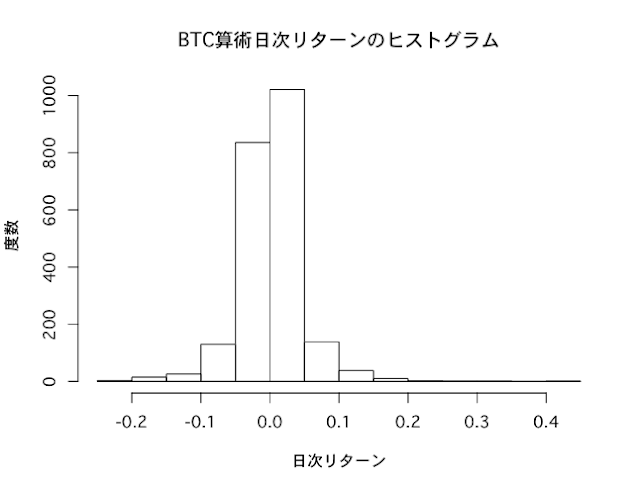
分布の歪み具合を示すのが歪度です。正規分布のように左右対称な分布では、歪度は0になります。
BTC日次収益率の歪度は0.5です。歪度が正であるということは、分布のピークが左側にあり、右側の裾が広い分布であることを意味します。つまり、極端に高いリターンが出やすいと言えます。
#歪度:正規分布は0、正なら右裾が広い skewness(BTC_return_daily) #[1] 0.5234792
尖度は分布の尖り具合を示します。正規分布は尖度3(0とする定義もあり)であり、これより大きければ、分布は平均の周りで尖った、左右に裾野が広い分布になります。
BTC日次収益率の尖度は12であり、正規分布より極端に「尖った」、そして「裾野の広い」分布になります。つまり、極端に高い・低いリターンが出現しやすいことを意味します。
#尖度:正規分布が3 kurtosis(BTC_return_daily) #[1] 12.9556
リターンの実現値が、どの範囲でどのくらいの頻度で出現したかを見るグラフが、ヒストグラムです。
BTC日次収益率のヒストグラムを描いてみます。
正規分布のヒストグラムは左右対称のベルのような形をしていますが、BTC収益率のヒストグラムはやや右に裾野が厚く、かつ裾野が広がっている印象を受けます。
hist(BTC_return_daily,main="BTC算術日次リターンのヒストグラム",xlab="日次リターン",ylab="度数")
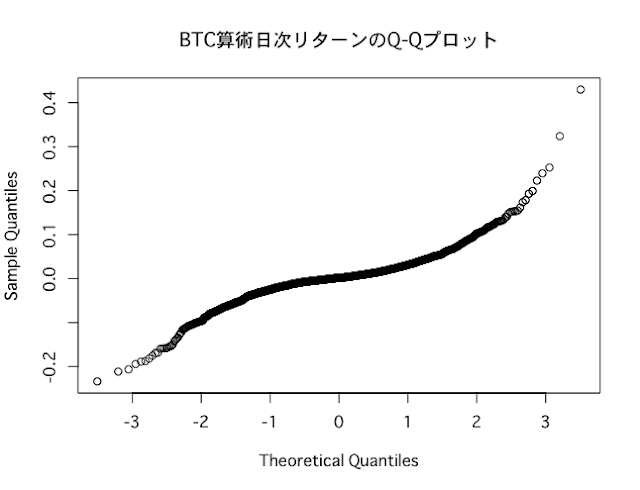
BTCの日次データをQ-Qプロットしてみると、以下のように曲線を描いており、正規分布に近いとは言えません。
qqnorm(BTC_return_daily,main="BTC算術日次リターンのQ-Qプロット")
> shapiro.test(BTC_return_daily) Shapiro-Wilk normality test data: BTC_return_daily W = 0.87881, p-value < 0.00000000000000022
> ks.test(BTC_return_daily, "pnorm", mean=mean(BTC_return_daily), sd=sqrt(var(BTC_return_daily))) One-sample Kolmogorov-Smirnov test data: BTC_return_daily D = 0.11752, p-value < 0.00000000000000022 alternative hypothesis: two-sided 警告メッセージ: ks.test(BTC_return_daily, "pnorm", mean = mean(BTC_return_daily), で: コルモゴロフ・スミノフ検定において、タイは現れるべきではありません
このように、確率分布が標準的なファイナンスの仮定と異なることにより、やや慎重な議論が必要になってきます。
投資においては、為替や株式等よりも変動性が大きく、また極端に高いもしくは低いリターンが出やすいという点に気をつける必要があります。
ビットコインを始めとする仮想通貨のデータを扱う際には、この分布の特性をよく踏まえる必要があります。
関連記事>>ビットコインはバブルである
最近のコメント