こんにちは、毛糸です。
前回、Rライブラリ「crypto」を用いて、仮想通貨の価格が簡単に取得できることを説明しました。
>>仮想通貨の価格ヒストリカルデータを取得する方法|Rライブラリcryptoの使い方
今回は「crypto」を使って取得したBitcoin(BTC)の価格情報を分析します。
BTC価格の時系列データを分析することで、BTCの期待リターン、リスクが極めて高いことがわかりました。
また、ヒストグラムと「正規性の検定」により、BTCのリターンは正規分布に従わないこともわかりました。
cryptoパッケージによるBTC価格の取得とリターンのデータ
cryptoパッケージのcrypto_history()関数を用いて、BTC価格のヒストリカルデータを取得します。
>>仮想通貨の価格ヒストリカルデータを取得する方法|Rライブラリcryptoの使い方
#crypto_history(coin = NULL, limit = NULL, start_date = NULL,
#end_date = NULL, coin_list = NULL, sleep = NULL)
#仮想通貨の価格等情報を取得
#dateはyyyymmdd形式で。NULLとすると最長期間
BTC<-crypto_history(coin = "BTC",
start_date = NULL,end_date = NULL)
BTC価格を時系列データとして読み込みます。
BTC_price<-ts(BTC$close,start=BTC$date[1])
plot(BTC_price,type="l")
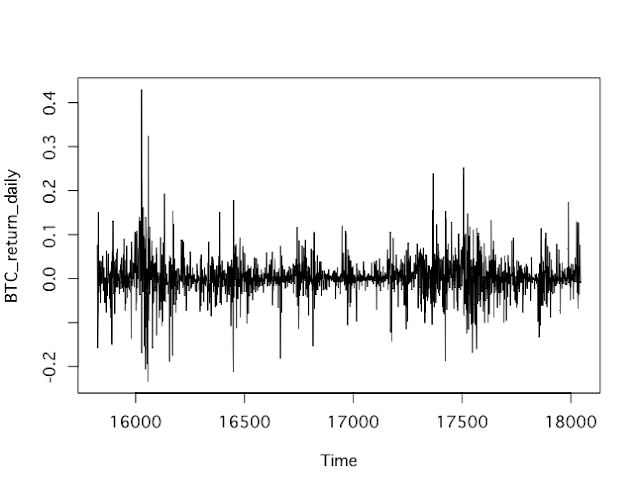
日次収益率を計算し、プロットしてみましょう。
#日次収益率
BTC_return_daily<-diff(BTC_price,lag=1)/lag(BTC_price,k=-1)
plot(BTC_return_daily,type="l")
以下ではこの日次収益率データを使って、BTCの収益率の統計分析をしていきます。
基本統計量
期待リターン(平均)
日次収益率の平均をとることで、日次期待リターンを推定できます。結果は、日次リターンが0.28%、簡易的に年率換算すると102%となりました。株式のリターンが年率5%ほどと言われていますから、驚異的な水準です。
#日次収益率の平均(期待リターン)(%)
mean(BTC_return_daily)*100
#[1] 0.2808807
#年率換算(%)
mean(BTC_return_daily)*100*365
#[1] 102.5215
リスク(標準偏差)
日次収益率の標準偏差を計算することで、日次収益率のリスクを推定できます。結果は、日次ベースの標準偏差が4.3%、簡易的に年率換算すると82%となりました。株式のリスクが年率25%ほどと言われていますから、とてつもなくハイリスクであることがわかります。
#標準偏差(%)
sd(BTC_return_daily)*100
#[1] 4.333606
#年率換算(%)
sd(BTC_return_daily)*100*365^0.5
#[1] 82.79343
歪度
歪度と尖度の計算には、「moments」ライブラリのskewness()、kurtosis() 関数を用います。
install.packages("moments")
library(moments)
分布の歪み具合を示すのが歪度です。正規分布のように左右対称な分布では、歪度は0になります。
BTC日次収益率の歪度は0.5です。歪度が正であるということは、分布のピークが左側にあり、右側の裾が広い分布であることを意味します。つまり、極端に高いリターンが出やすいと言えます。
#歪度:正規分布は0、正なら右裾が広い
skewness(BTC_return_daily)
#[1] 0.5234792
尖度
尖度は分布の尖り具合を示します。正規分布は尖度3(0とする定義もあり)であり、これより大きければ、分布は平均の周りで尖った、左右に裾野が広い分布になります。
BTC日次収益率の尖度は12であり、正規分布より極端に「尖った」、そして「裾野の広い」分布になります。つまり、極端に高い・低いリターンが出現しやすいことを意味します。
#尖度:正規分布が3
kurtosis(BTC_return_daily)
#[1] 12.9556
BTC収益率(リターン)は正規分布にしたがうか?(正規性の検定)
ファイナンス(金融工学)では、資産のリターンは正規分布に従うと仮定されることが多いです(資産価格が対数正規分布、資産価格が幾何ブラウン運動、も同様の意味です)。
BTC収益率は正規分布に従うのか、確かめてみましょう。
すでに、BTC収益率の歪度が0.5(正規分布なら0)、尖度が12(正規分布なら3)であることは確認しましたので、正規分布ではないような気がしますが、別の視点からも確認します。
本性の内容は下記記事を参考にしています。
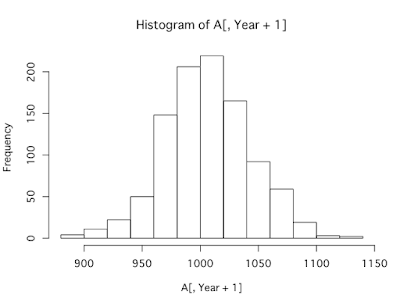
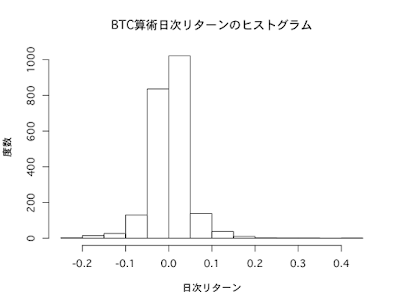
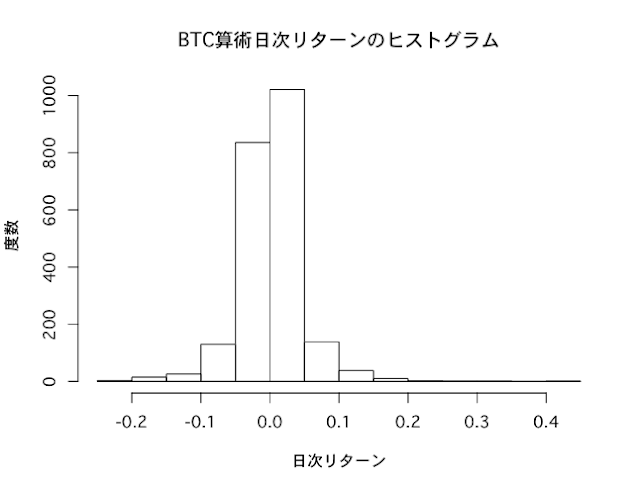
ヒストグラム
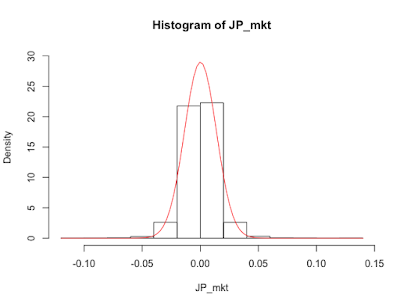
リターンの実現値が、どの範囲でどのくらいの頻度で出現したかを見るグラフが、ヒストグラムです。
BTC日次収益率のヒストグラムを描いてみます。
正規分布のヒストグラムは左右対称のベルのような形をしていますが、BTC収益率のヒストグラムはやや右に裾野が厚く、かつ裾野が広がっている印象を受けます。
hist(BTC_return_daily,main="BTC算術日次リターンのヒストグラム",xlab="日次リターン",ylab="度数")
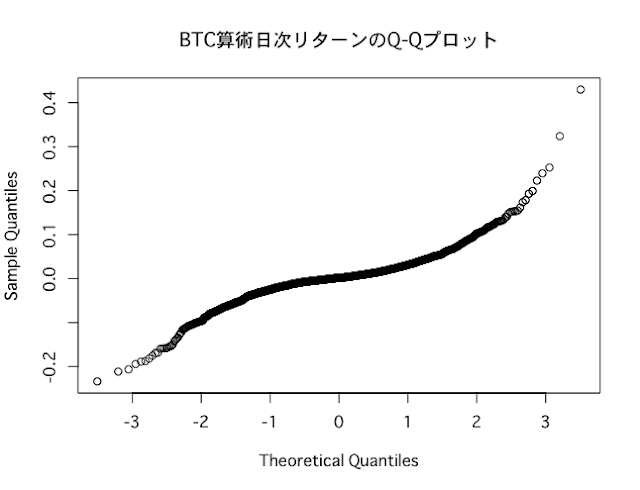
Q-Qプロット
Q-Qプロットは、与えられたデータがある確率分布とどれくらい「ずれているか」を図示したものです。データをQ-Qプロットしたとき、データが45度線(y=xのグラフ)に沿って並んでいれば、理論上の分布と近いという根拠になります。Rではqqnorm()関数によって、正規分布を仮定した場合のQ-Qプロットを描画できます。
BTCの日次データをQ-Qプロットしてみると、以下のように曲線を描いており、正規分布に近いとは言えません。
qqnorm(BTC_return_daily,main="BTC算術日次リターンのQ-Qプロット")
シャピロ・ウィルク検定
シャピロ・ウィルク検定は、「データが正規分布に従う」という帰無仮説に関する検定です。したがって、シャピロ・ウィルク検定で計算されたp値が小さければ、帰無仮説を棄却、つまり「データは正規分布に従わない」ということが言えます。Rではshapiro.test()を使います。
検定の結果、p値はほぼ0であり、「BTC日次収益率は正規分布に従わない」と結論付けられます。
> shapiro.test(BTC_return_daily)
Shapiro-Wilk normality test
data: BTC_return_daily
W = 0.87881, p-value < 0.00000000000000022
コルモゴロフ・スミルノフ検定
コルモゴロフ・スミルノフ検定は、「データが指定した確率分布に従う」という帰無仮説に関する検定です。したがって、正規分布に関するコルモゴロフ・スミルノフ検定を行ったときにp値が小さければ、帰無仮説を棄却、つまり「データは正規分布に従わない」ということが言えます。Rではks.test()を使います。
検定の結果、p値はほぼ0であり、「BTC日次収益率は正規分布に従わない」と結論付けられます。
> ks.test(BTC_return_daily, "pnorm", mean=mean(BTC_return_daily), sd=sqrt(var(BTC_return_daily)))
One-sample Kolmogorov-Smirnov test
data: BTC_return_daily
D = 0.11752, p-value < 0.00000000000000022
alternative hypothesis: two-sided
警告メッセージ:
ks.test(BTC_return_daily, "pnorm", mean = mean(BTC_return_daily), で:
コルモゴロフ・スミノフ検定において、タイは現れるべきではありません
なお、警告メッセージは同一データが存在するときに発生します。連続確率分布では同一の値が実現する確率は0なので、本来生じるべきではないというアラートですが、今回は厳密な議論をしているわけではないので、スルーします。
以上のような検討の結果、いずれの方法でも、BTC日次収益率は正規分布に従わないという結論が得られました。
ビットコインの収益率が正規分布に従わないとなにが困るか
ビットコインの収益率が正規分布に従わないということは、収益率が正規分布に従うと仮定して展開される多くのファイナンス理論の道具が使えないことになります。
たとえば、オプションの価格公式であるブラック・ショールズ式は、資産価格が幾何ブラウン運動に従うこと(つまり収益率が正規分布に従うこと)を仮定しています。
したがって、ビットコインのオプションが組成されたときに、そのオプションの価格をブラック・ショールズ式で評価するのと、意思決定を誤ります。
また、将来の投資運用の成績をシミュレーションする「投資シミュレーションプログラム」も、資産の収益率に正規分布を仮定しているため、仮想通貨投資には利用できません。
このように、確率分布が標準的なファイナンスの仮定と異なることにより、やや慎重な議論が必要になってきます。
投資においては、為替や株式等よりも変動性が大きく、また極端に高いもしくは低いリターンが出やすいという点に気をつける必要があります。
まとめ
Rライブラリ「crypto」を用いて、ビットコインの価格情報を取得し、日次リターンの分析を行ってみました。
ビットコインの収益率は極めてハイリスク・ハイリターンであり、また、ファイナンスで通常仮定される正規分布とは大きく異なる性質を持っています。
参考記事
リンク
データ解析その前に: 分布型の確認と正規性の検定 #rstatsj(
リンク)
Leihcrev’s memo 入門本編 8章 確率分布(
リンク)
統計解析フリーソフト R の備忘録頁 ver.3.1 63. 正規性の検定(
リンク)









最近のコメント